

消息队列作为高并发系统的核心组件之一,能够帮助业务系统解构提升开发效率和系统稳定性。作为目前主流的MQ之一,RocketMQ支持事务消息、顺序消息、批量消息、定时消息、消息回溯等功能,并具有以下优势:
支持严格的消息顺序
支持 Topic 与 Queue 两种模式
亿级消息堆积能力
比较友好的分布式特性
同时支持 Push 与 Pull 方式消费消息
如何完整的实施RocketMQ性能测试呢?本文从测试方案及计划定制、测试场景搭建、测试数据分析、测试总结等方面为大家带来详细的操作步骤。
1.需求背景
在1台生产者、1台broker、1台namesrv 、1台消费者的架构中,测试字节为1024B,客户端线程数:256、128、64、32,MQ队列大小为16、32、64、128,进行RocketMQ的生产与消费的性能测试,找出最大tps。
RocketMQ作为一款纯java、分布式、队列模型的开源消息中间件,支持事务消息、顺序消息、批量消息、定时消息、消息回溯等。官方文档地址:http://rocketmq.apache.org/
2.需求分析
针对需求,现需测试下列几个场景:
RocketMQ测试场景为只生产,查看发送的最大的tps为多少
RocketMQ测试场景为只消费,查看消费的最大tps为多少
RocketMQ测试场景为一边生产一边的消费,最大的tps为多少
RocketMQ更改配置后查看生产、消费、以及一边生产一边消费与没有更改配置前的数据差异
3.基础介绍
3.1 术语介绍
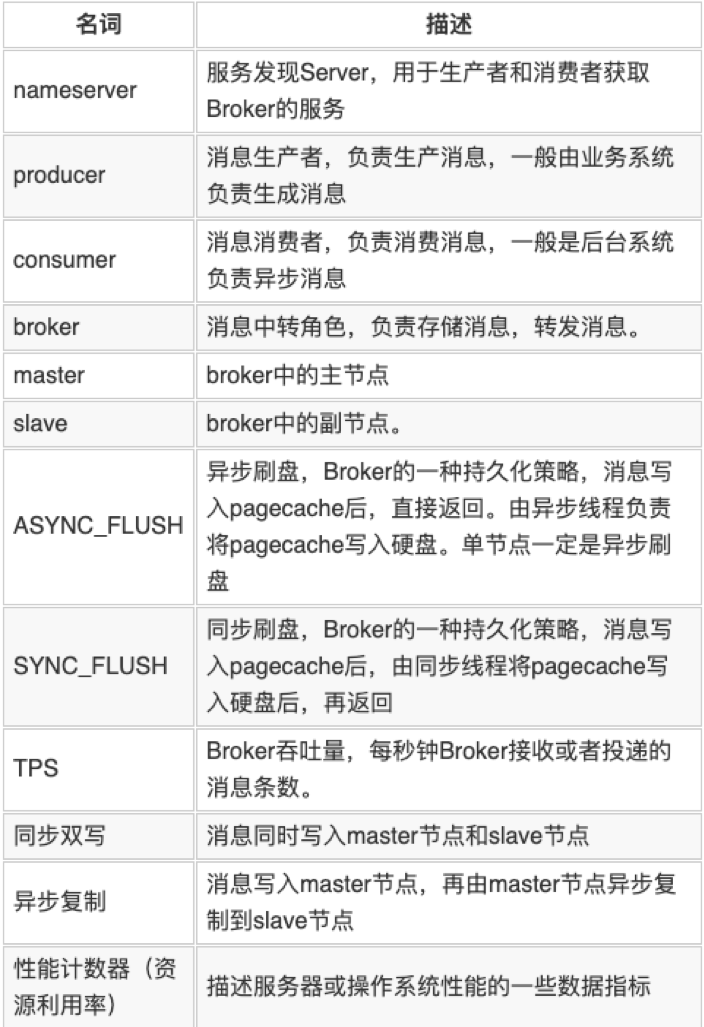
3.2 性能测试方法论
性能测试的前期准备
Ø 分析业务场景 场景内容有哪些,范围较广,可与开发、产品,讨论确定本次测试的范围
Ø 分析测试策略 得到设计的测试场景有哪些
Ø 分析生产环境 搭建测试环境,建立一个小型相同的测试环境
Ø 选择测试工具 用什么方式来测试性能
性能测试的目的
Ø 性能测试则通过提前模拟场景压力,来发现系统中可能的瓶颈,提前修复这些bug,减少服务器宕机的风险。
Ø 性能测试还可以用来评估待测软件在不同负载下的运作状况,可以针对某些数据得到一些决策
性能下降曲线分析法
Ø 性能随用户数增长而出现下降趋势的曲线
Ø 性能主要指响应时间
Ø 分为:单用户区域、性能平坦区、压力区域、性能拐点
4.测试环境
4.1 架构图
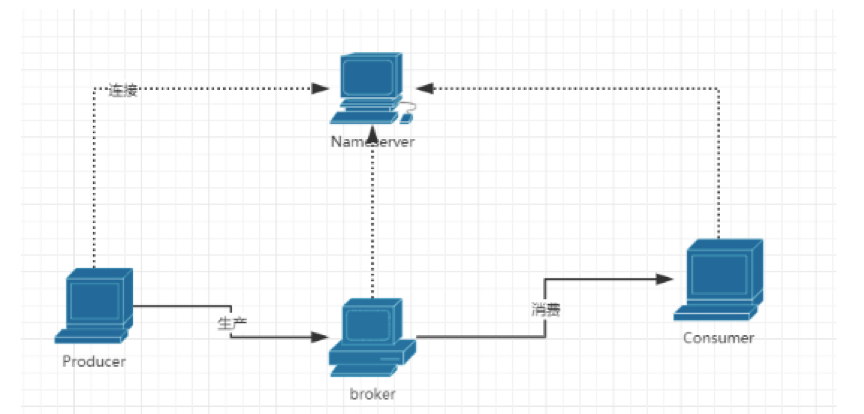
实线为数据流向线 虚线为网络连接
4.2 被测系统
RocketMQ作为一款纯java、分布式、队列模型的开源消息中间件,支持事务消息、顺序消息、批量消息、定时消息、消息回溯等
4.3 测试资源
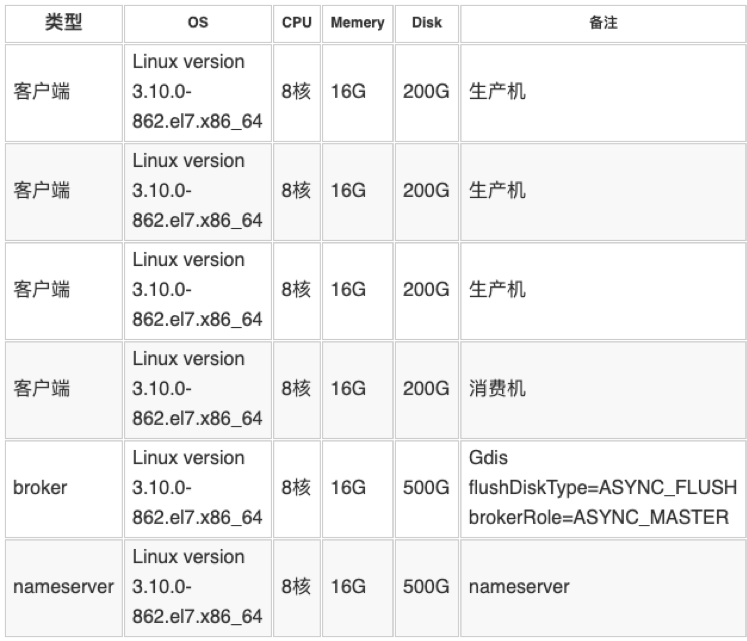
4.4 测试工具
4.4.1 工具说明
压测工具使用RocketMQ源码中提供的benchmark工具,因为对mq做了二次封装,重新编译benchmark工具源码,打包生成一个jar文件,主要使用是的类为
producer 文件:
用于生产消息,测试时需要提前创建topic,如我们使用的生产的topic 为zj_test_topic,w 参数可更改线程数 s参数可更改信息大小 k是启用口令,默认启动时是64个线程,1024字节大小
java

使用方式:
java -jar XX.jar 的方式运行打包好的jar文件 可输入不同参数,有不同的效果,不输入参数默认是使用64线程1028B字节
效果展示:

返回数据详解:
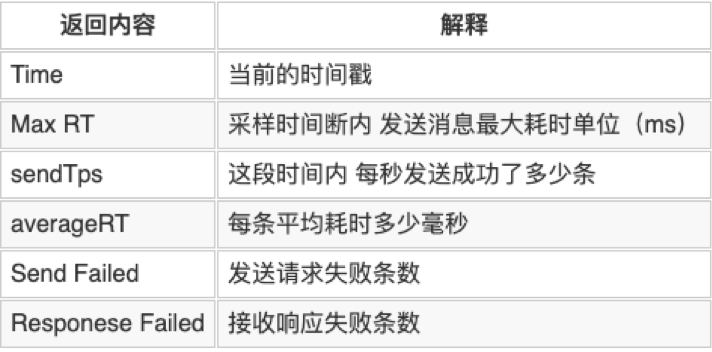
Consumer文件:
用于消费消息,Topic 还是使用的:zj_test_topic,group组为benchmark_consumer,参数有这几项,需要提前创建消费组
java

效果展示

4.5 测试用例
5. 数据采集
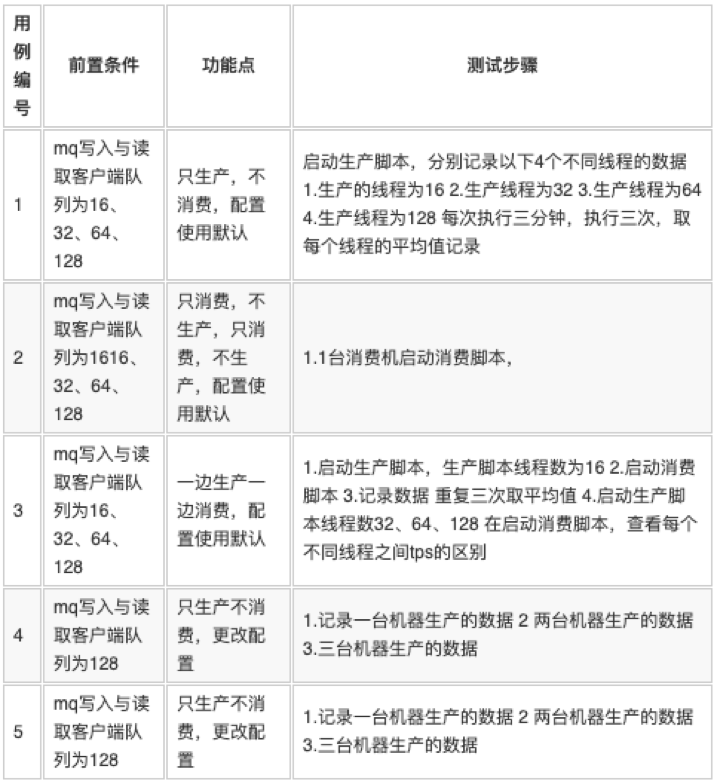
5.1 只生产不消费数据
5.1.1 mq 的服务端线程为128
以下数据在8核16G Gdisk 500G 本地磁盘的测试数据, 客户端cpu消耗是在11%左右,meery是在3.8%。
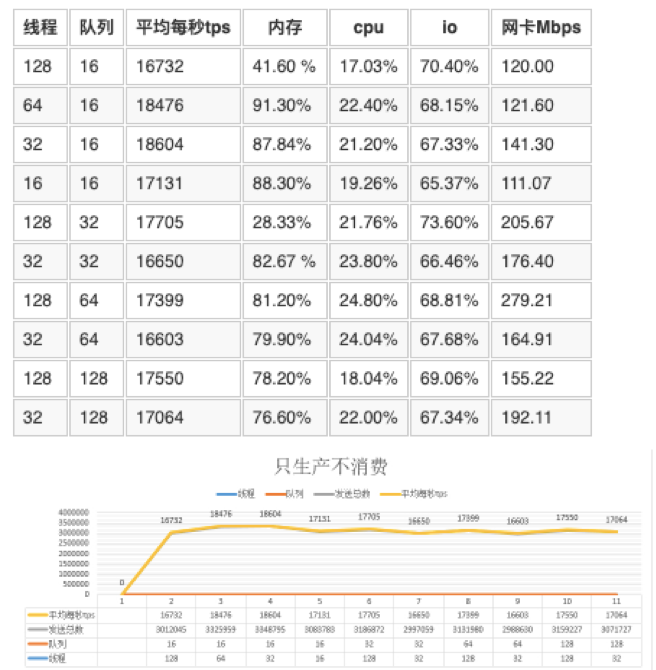
mq的服务端线程数为32
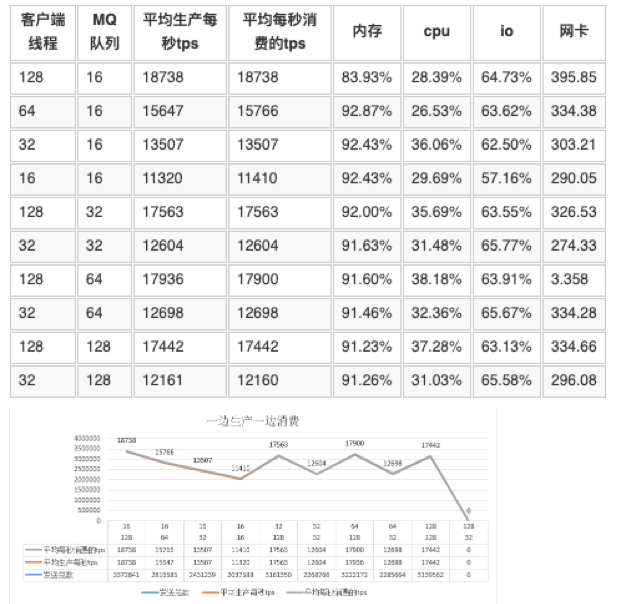
5.2 一边生产一边消费
mq 的服务端线程数为32
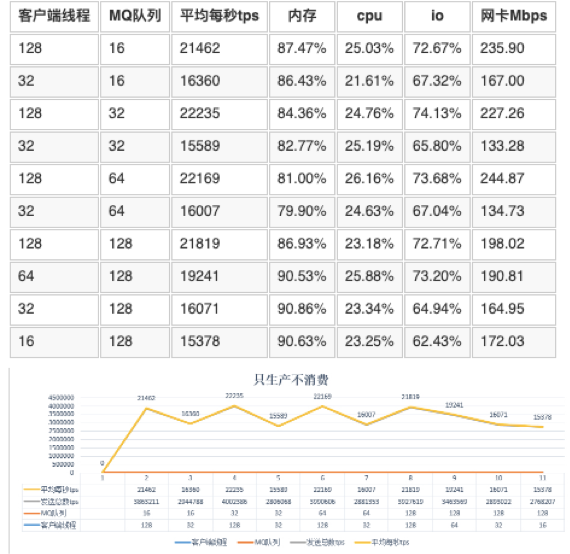
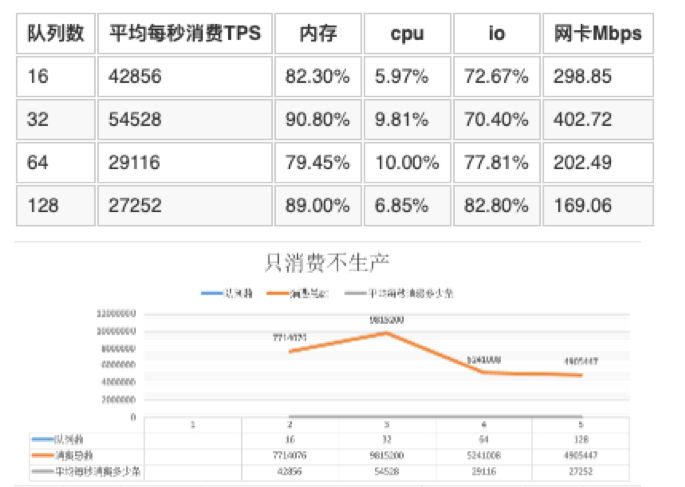
5.3 只消费不生产
mq的服务端线程数为32
5.4 更改配置进行只生产与只消费

5.4.1 更改测试环境配置1:
配置如下:

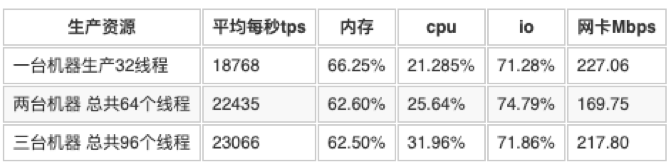
只生产不消费,mq队列数为128
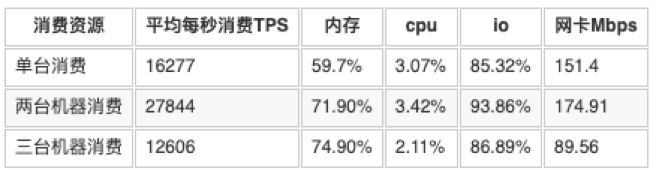
只消费不生产,mq队列数为128

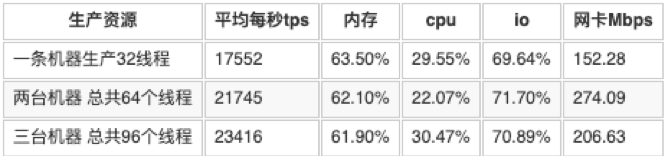
5.4.2 更改测试环境配置2
配置如下:

只生产不消费,mq队列数为128
只消费不生产,mq队列数为128
6. 数据分析
表5.1.1数据分析
在64线程和128的线程相应都出现过失败,内存使用率是在91%。
从数据中看出32线程 在16个队列,线程池为128 配置是最优,线程数增多,tps并没有上升。
在开大了队列数的情况下,32的线程与128的线程平均的tps差距不是很大,差距是在1000左右,且128的每秒耗时还很长 结论:32线程在目前配置最优。
服务器io使用率在67%左右,cpu在21% 服务器并没有达到一个性能最优点,应该还不是瓶颈。
表5.1.2数据分析
设置线程池的数据是32,只生产的最大的tps是22235。比表5.1.1 配置的服务端线程为128。
发送的tps会更多,说明在8C 16G mq的服务端线程配置为32是最优。
存在同样一个问题,设置不同大小的线程数,服务器的压力并没有上去。
线程数增大,io的利用率有上升
表 5.2中分析
生产的最大tps是18783 ,消费最大的tps 也是18738 ,在消费过程中,64的队列有出现过消费重试的情况。
128的线程与32的线程数据,增长不明显
表5.3中分析
消费多少受网卡限制,网络流量大的消费数会更多。
只消费不生产,每秒最大的消费是48435,内存是在90.08 cpu消耗在9.81 io是在70.4 网卡是在402.72Mbps。
表5.4.1中分析
mq的配置进行更改,两台机器生产,总共64线程,tps也能达到22435。
表5.4.2中分析
与表5.4.1中进行对比,更改DirectMemorySize,对生产没有太多影响,但是对消费单台上来看是有影响。
7. 测试结论
只生产不消费场景,最大的tps是22235。
一边生产一边消费的场景,最大的tps生产是18738,消费最大的tps是18738。
只消费不生产,最大的tps是48435。
配置如下

0条评论