

Apache Kylin是当下十分流行的分布式分析引擎,kylin能提供它能在亚秒内查询巨大的Hive表。但是hive维度过大的时候可能会产生维度“灾难”,导致查询时间指数级的增加。现在我就介绍一下kylin cube构建中常用的优化工具——Aggregation Group(聚合组)。
以我们常用的构建方法在kylin提供web ui上构建新的cube 如下图所示。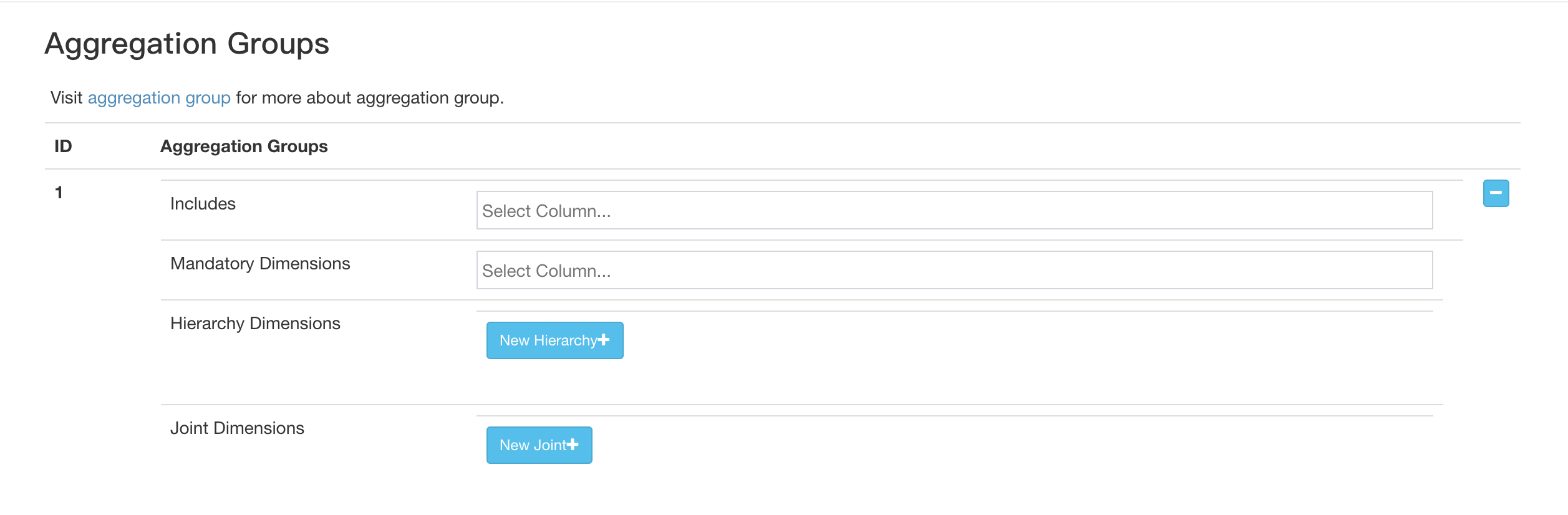
首先,我们应该了解cube。cube是所有cuboid的一个集合。而没有一个cuboid都是一种维度的组合。下面举个栗子:
假如新建的cube中有A,B,C,D四个维度,根据排列组合它会产生16个cube。16个组合如下:
A,B,C,D,AB,AC,AD,BC,BD,CD,ABC,ABD,BCD,ACD,ABCD,还有一个是不包括所有维度的cube。
根据kylin预计算的特性,会将上述所有组合计算一次存储与hbase当中。但是如果某些组合是没有意义的呢?假如A代表的是时间,在没有时间的维度下其他的几个维度就失去统计的意义。那么在上诉的16中组合中没有A的组合就永远不会被需要,那么产生的这些cuboid就是没有意义的,浪费空间和计算资源,影响查询速度。
所以官方就在构建cube的时候提供了Aggregation Group(下称聚合组),在构建图中可以看Aggregation Group下都有这几行选项:
Mandatory(强制维度)、Hierarchy(层级维度)、Joint(联合维度)
下面浅析一下这几个维度的作用:
Mandatory(强制维度):例如上述的A维度就可以设置为强制维度,所有的查询条件都需要查询的维度,可以设置为强制维度。
Hierarchy(层级维度):例如存放的维度是年(A)、月(B)、日(C)三个维度。单独拿出月,或日是没有意义的,可以设置为层级维度(所以设置的层级维度,就不会出现下列组合:B、C、BC)。
Joint(联合维度):每个联合中包含两个或更多个维度,如果某些列 形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一 起出现,要么都不出现。
注:聚合组可以大大减少cube的体积,但滥用聚合出会导致当出现聚合组之外的查询时,计算引擎超负荷工作导致查询慢或者查询不到结果的问题。
0条评论