

Java语法糖介绍
什么是语法糖
语法糖(Syntactic Sugar),也称糖衣语法,指的是在计算机语言中添加的某种语法,对语言的编译结果和功能并没有什么影响,但却能方便程序员使用该语言。
Java编译过程

Java语法糖作用于.java文件编译成.class字节码的过程,无论是否使用语法糖都可以生成相同的字节码,JVM对于语法糖的存在无感知
Javac编译的处理流程
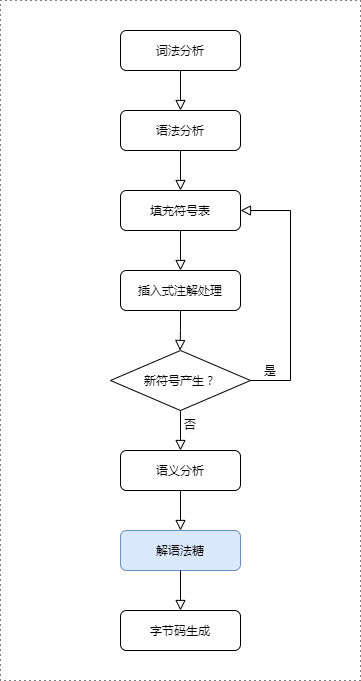
将高版本支持的语法特性还原回原始的基础语法结构的过程,称为解语法糖。
了解、学习Java语法糖的好处
- 精简代码,提高代码的可读性和严谨性
- 编码更便利,提高开发效率
- 看清程序编译执行的本质
Java语法糖代码分析
自动装箱、拆箱
编译前的代码
public int sum(Integer a, Integer b) {
return a + b;
}编译后的等价代码
public int sum(Integer a, Integer b) {
return a.intValue() + b.intValue();
}遍历循环
编译前的代码
String[] arr = new String[] { "ABC", "123", "def" };
for (String str : arr) {
System.out.println(str);
}编译后的代码
String[] arr = new String[] { "ABC", "123", "def" };
int length = arr.length;
for (int i = 0; i < length; ++i) {
String str = arr[i];
System.out.println(str);
}编译前的代码
List<String> list = Arrays.asList("A", "B", "C");
for (String str : list) {
System.out.println(str);
}编译后的等价代码
List list = Arrays.asList("A", "B", "C");
Iterator it = list.iterator();
while(it.hasNext()) {
String str = (String) it.next();
System.out.println(str);
}这个例子可以看到,for in 循环的代码编译后变成了使用Iterator的方式进行遍历,for in 循环是帮助我们简化了这部分代码。另外,我们看到在编译后,泛型<String>被去掉了,这也是一个语法糖。
泛型
Java的泛型实现也称为类型擦除式泛型,泛型类型只在java源码中存在,编译后的字节码文件中,全部泛型都被替换为原来的裸类型,并且在相应的地方插入了强制类型转换代码。
编译前的代码
Map<String, String> map = new HashMap<>();
map.put("Hello", "World");
System.out.println(map.get("Hello"));编译后的等价代码
Map map = new HashMap();
map.put("Hello", "World");
System.out.println((String) map.get("Hello"));反例1,下面这段代码编译会报错。我们不能用泛型直接创建泛型对象或泛型数组,因为类型T在编译后的字节码中是不存在的。而在C++或者C#这样的编程语言里是可以这么编写代码的,因为编译后泛型类型是保留的。
public class Creator<T> {
public T create() {
return new T();
}
public T[] createArray(int size) {
return new T[size];
}
public boolean testInstanceOf(List<T> list) {
return list instanceof List<String>;
}
}变长参数
编译前的代码
public void foreach(String... arr) {
System.out.println(arr.getClass());
}编译后的代码
public void foreach(String[] arr) {
System.out.println(arr.getClass());
}条件编译
编译优化,对不可能会执行的代码进行剪枝
public void test(String str) {
if (false) {
System.out.println("if语句的这三行代码在编译后的class文件中不存在");
}
System.out.println(str);
}内部类
成员内部类可以自由地访问外部类的成员变量,无论是否是private的。如下示例中,Inner这个内部类可以访问到Outer外部类的私有成员name。
public class Outer {
private String name;
public Outer(String name) {
this.name = name;
}
public void printName() {
new Inner().printName();
}
private class Inner {
public void printName() {
System.out.println(name);
}
}
}这是怎么做到的呢? 通过查看编译后的.class文件,我们可以看到目录下存在如下文件
Outer.class
Outer$Inner.class
编译器自动为内部成员类的构造函数增加了一个参数,将外部类的实例通过第一个参数传递进去,这样子内部类就持有了外部类实例的句柄,可以访问外部类的成员和方法。
为了能访问私有成员,编译器为外部类自动生成了对应的静态方法,以支持合法地访问私有成员。
等价的代码为:
public class Outer {
private String name;
public Outer(String name) {
this.name = name;
}
public void printName() {
new Inner(this).printName();
}
static String access$100(Outer outer) {
return outer.name;
}
}
class Inner {
private Outer outer;
Inner(Outer outer) {
this.outer = outer;
}
public void printName() {
System.out.println(outer.access$100(outer));
}
}玫举类
玫举类是JDK 1.5支持的特性,实际上也是通过语法糖来实现的
编译前
public enum Operator {
ADD("+"),
SUBTRACT("-"),
MULTIPLY("*"),
DIVIDE("/"),
;
private String code;
Operator(String code) {
this.code = code;
}
}编译后
public class Operator extends java.lang.Enum<Operator> {
private String code;
private Operator(String name, int ordinal, String code) {
super(name, ordinal);
this.code = code;
}
public static final Operator ADD;
public static final Operator SUBTRACT;
public static final Operator MULTIPLY;
public static final Operator DIVIDE;
private static final Operator[] $VALUES;
static {
ADD = new Operator("ADD", 0, "+");
SUBTRACT = new Operator("SUBTRACT", 1, "-");
MULTIPLY = new Operator("MULTIPLY", 2, "*");
DIVIDE = new Operator("DIVIDE", 3, "/");
$VALUES = new Operator[] { ADD, SUBTRACT, MULTIPLY, DIVIDE };
}
public static Operator[] values() {
return $VALUES;
}
public static Operator valueOf(String name) {
return Enum.valueOf(Operator.class, name);
}
}断言语句
assert是JDK 1.4引入的关键字,用于在调试和单元测试中发现问题。现在单元测试框架的功能非常强大,所以assert已经很少有人使用了。
编译前
public class Main {
public static void main(String[] args) {
System.out.println("before assert");
assert args == null;
System.out.println("after assert");
}
}编译后
public class Main {
static final boolean $assertionsDisabled = !Main.class.desiredAssertionStatus();
public static void main(String[] args) {
System.out.println("before assert");
if (!$assertionsDisabled && args != null) {
throw new AssertionError();
}
System.out.println("after assert");
}
}assert语句默认是不执行的,只有在启动参数中增加-enableassertions或-ea才能开启。Java编译器在Class.desiredAssertionStatus()方法中判断启动参数是否启用assert,并作用在assert语句上。
数值字面量
编译前
int i = 10_0000;
System.out.println(i);编译后
int i = 100000;
System.out.println(i);对玫举/字符串的switch支持
switch从JDK 7开始支持String,实际上switch的对象不管是String还是玫举,都是先转成int类型进行比较
String编译前
public void test(String str) {
switch (str) {
case "ABC":
System.out.println("str is string ABC");
break;
case "123":
System.out.println("str is number 123");
break;
}
}String编译后
public void test(String str) {
int code = str.hashCode();
switch (code) {
case 48690:
if ("ABC".equals(str)) {
System.out.println("str is string ABC");
}
break;
case 64578:
if ("123".equals(str)) {
System.out.println("str is number 123");
}
break;
}
}玫举编译前
public void test(Operator operator) {
switch (operator) {
case ADD:
System.out.println("+");
break;
case SUBTRACT:
System.out.println("-");
break;
}
}玫举编译后
public void test(Operator operator) {
int ordinal = operator.ordinal();
switch (ordinal) {
case 0:
System.out.println("+");
break;
case 1:
System.out.println("-");
break;
}
}try-with-resource
编译前
public void test() throws IOException {
try (FileReader fileReader = new FileReader("D:/abc.txt")) {
int readed = fileReader.read();
System.out.println(readed);
}
}编译后的等价代码
public void test() throws IOException {
FileReader fileReader = null;
Throwable throwable = null;
try {
fileReader = new FileReader("D:/abc.txt");
int readed = fileReader.read();
System.out.println(readed);
} catch (Throwable e) {
throwable = e;
throw e;
} finally {
if (fileReader != null) {
if (throwable != null) {
try {
fileReader.close();
} catch (Throwable e) {
throwable.addSuppressed(e);
}
} else {
fileReader.close();
}
}
}
}Lambda
Lambda是JDK 8加入的新特性,不是用内部类来实现的,而是依赖JDK 7加入的InvokeDynamic指令。下面我们通过一个例子来说明Lambda的实现过程。
public class LambdaTest {
public void test() {
List<String> list = Arrays.asList("A", "B", "C");
list.forEach(str -> System.out.println(str));
}
}编译后的伪代码(InvokeDynamic指令的执行和以下Java代码不一致,但是执行流程和逻辑是相同的)
/**
* 实际生成的.class文件中没有cs$test$0这个字段
* 这里想要表达的意思是:JVM在执行InvokeDynamic指令时,会将第一次动态生成的CallSite代理类缓存起来,在之后就是直接调用以提高性能
**/
private static volatile CallSite cs$test$0;
public void test2() throws NoSuchMethodException, IllegalAccessException, LambdaConversionException {
List list = Arrays.asList("A", "B", "C");
if (cs$test$0 == null) {
MethodHandles.Lookup caller = MethodHandles.lookup();
String invokedName = "accept";
MethodType invokedType = MethodType.methodType(Consumer.class);
MethodType samMethodType = MethodType.methodType(void.class, Object.class);
MethodType instantiatedMethodType = MethodType.methodType(void.class, String.class);
MethodHandle implMethod = caller.findStatic(caller.lookupClass(), "lambda$test$0", instantiatedMethodType);
cs$test$0 = LambdaMetafactory.metafactory(caller, invokedName, invokedType, samMethodType, implMethod, instantiatedMethodType);
}
list.forEach((Consumer) cs$test$0.getTarget());
}
private static void lambda$test$0(String str) {
System.out.println(str);
}编译器在当前类中自动加入了lambda$test$0这个方法,是最终的代码执行位置。LambdaMetafactory.metafactory方法的目的是返回将最终代码执行方法包装起来的动态类。
Java语言改进趋势
小版本快速迭代
Sun公司时代的JDK版本发布时间周期非常长,没有固定时间,还发生过未在承诺的时间内发布版本的事件。Oracle收购Java之后,将庞大的版本发布计划拆分成一系列较小的可控的版本特性改进计划,保持每年发布2个大版本的节奏。小跑快跑的策略,解决了之前版本难产的问题,成功挽回了开发者的信心。目前JDK 15是最新的JDK版本。
保持向后兼容
Java语言作为一个比较老旧的语言,有很多特性在现在看来设计得不够合理,便利性上也没有现在很多其他语言的简捷语法好。但是Java的优势就在于它的生态,Java的使用用户量非常大,用Java编写的并且仍然还在持续使用的代码量比其他语言多几个量级。Java语言规范在很早以前,就把保持向后兼容性作为必须要持续严格遵守的规则写进去了,这很好地保证了稳定性。用户在JDK 1.2版本上编写的代码,至今仍然可以在JDK 15上面流畅运行。
提高语言易用性
JDK最近的几个版本,已经加入了一些让语言更易用的小语法糖,比如try-with-resources、多行文本字符串、switch支持字符串、instanceof模式匹配。这些语法改进对开发者使用上带来了便利性,之后还会继续在语法上面改进,提高语言易用性。
吸收其他语言优秀的语法特性
新兴的编程语言各有各的独到之处,某些特性设计得比较合理。Java语言吸收其中适合Java静态类型语言的一些特性,取长取短。最近几个JDK版本的一些特性,很多人说是抄Kotlin、Scala、groovy等等,确实是这样的。这些运行在JVM上的其他语言,和Java的分歧不大,更容易借鉴和吸收。但是Java也不是全都接受,语法糖太多也不一定是好事,不合理的语法设计、太多的选择有可能增加开发者学习成本、维护成本。
持续改善性能
由于历史原因,Java的一些特性被人诟病比较多,比如自动装箱拆箱、序列化。Java现在已经有改进项目在尝试引入可直接分配在栈上的内联类型,改进序列化机制,改进泛型特性。还有现在其他语言做得比较好的异步编程模型,Java正计划引入轻量级的纤程Fiber来解决这个问题。这些都是能提高Java语言执行性能的改进。
拥抱云原生
在容器化越来越流行的当下,go语言直接编译成高效的可执行二进制,非常契合容器化部署的模式。Java语言也推出了Graal编译器,能直接将.java代码编译成可执行的二进制,跳过字节码的中间过程。另外,JDK也试图提供更有效的API,提高访问外部内存和外部函数调用的能力。
重点孵化项目
Oracle通过成立了若干个孵化项目组,研究Java语言不同的改进方向。
以下是OpenJDK中正在进行的重要项目,可以提前了解以后版本的JDK中可能会增加的功能
- Amber
- Valhalla
- Loom
- Panama
Amber
Amber项目的目标是探索和孵化面向生产力改进的小改动,这些Java语言特性已被提交JEP并接受,大部分JEP特性已经加入到JDK版本中发布。
这个项目的一些成果已经被添加到JDK中,如下
- Java10中的var局部变量推断
- Java11中允许在swtich表达式的形参声明中使用var
- Java12中的swtich表达式
- Java14中的instanceof模式匹配
- JDK15中加入的record类型
Amber项目正在探索的新改动
- instanceof 模式匹配
- record 数据类
- 密封类型
- 序列化机制
参考文献:
https://openjdk.java.net/projects/amber/
instanceof 模式匹配
instanceof模式匹配的语法在JDK14首次加入,在JDK15中二次预览,预计在JDK16会成为正式的特性。
JDK16会对这个语法做以下两点改进
(1) 消除模式匹配变量的final特性。
(2) 对于instanceof匹配必然成功的情况,抛出编译错误。比如子类 instanceof 父类,必然成功。
代码示例
if (obj instanceof String s && s.length() > 5) {
flag = s.contains("jdk");
}record 数据类
record数据类以极简的方式创建一个数据载体类,自动生成对应的类字段、构造函数、getter方法、hashCode方法、toString方法,无setter方法。
代码示例
public record Point(int x, int y){};原来的写法比较繁琐
class Point {
private final int x;
private final int y;
Point(int x, int y) {
this.x = x;
this.y = y;
}
int x() { return x; }
int y() { return y; }
public boolean equals(Object o) {
if (!(o instanceof Point)) return false;
Point other = (Point) o;
return other.x == x && other.y = y;
}
public int hashCode() {
return Objects.hash(x, y);
}
public String toString() {
return String.format("Point[x=%d, y=%d]", x, y);
}
}密封类型
密封类在JDK15中首次预览,用于声明受限制继承的类,即只允许指定的类或接口继承此类。
public sealed class Animal permits Cat,Dog,Tiger{}序列化机制
java原生的二进制序列化实现比较鸡肋,序列化后的二进制体积较大,序列化的性能也比较低。很多开源的序列化框架比原生的好很多,官方打算改进这个特性。
Valhalla
Valhalla项目正在探索值类型方面的改进
- 内联类型
- 泛型改进
参考文献
https://wiki.openjdk.java.net/display/valhalla/
内联类型
通过将类型定义为inline类型,使得可以像int、float这样的值类型一样,内存直接分配到栈上,减少了GC的负担。另一方面少了对象头以及存储引用的内存,存储变得更高效。
public inline class Point {
int x;
int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
}泛型改进
泛型支持基本类型和内联类型,基至包括void。减少泛型类装箱拆箱的损耗,提高易用性。
List<int> intList = new ArrayList<>();
Map<String, void> map = new HasHMap<>();Loom
Loom项目的目标是提供易于使用、高吞吐量、高性能、轻量级并发的Java编程模型。正在探索的特性如下:
- 计算续体 Continuation
- 纤程 Fiber
- 尾调用消除 tail-call elimination
参考文献
https://wiki.openjdk.java.net/display/loom/
http://cr.openjdk.java.net/~rpressler/loom/loom/sol1_part1.html
计算续体 Continuation
计算续体是一段可以被暂停执行的代码。通过java.lang.Continuation提供的底层API,面向基础库的开发者。一般开发者不会直接使用,而是Fiber或Generator等高级API。
可以使用Continuation.yield暂停当前的执行者,让出CPU,并在将来可以触发继续运行;这个过程的切换可以在用户态下进行,非常轻量。
代码示例:
Continuation continuation = new Continuation(SCOPE -> {
System.out.println("first");
Continuation.yield(SCOPE);
System.out.println("second");
});
while (!continuation.isDone()) {
continuation.run();
}纤程 Fiber
由JVM自己实现和调度的轻量级线程,类似go语言的协程go routine。
功能预览
Thread.startVirtualThread(() -> {
System.out.println("Hello, Loom!");
});这里提一下quasar这个开源库,不依赖JVM底层,通过字节码增强的方式,实现了高性能轻量级的用户线程调度。就像Kotlin实现的协程可以在JVM上跑一样。
但是这个库,由于不是java语言底层的原生支持,使用上存在一些限制;通过抛出异常的方式来实现中断,性能上也达不到最优。
quasar在2018年底停止更新,其作者被Oracle邀请来主导Loom项目,将quasar的功能在JVM语言层面上进行实现。
quasar介绍传送门: http://docs.paralleluniverse.co/quasar/
尾调用消除 tail-call elimination
当一个函数调用另一个函数时,如果调用结束后没有其他代码需要执行,这就是一个尾调用。通过复用当前函数栈空间可以减少内存占用,提高性能,对于递归调用效果更明显。
public void methodA() {
System.out.println("A running.");
methodB();
}
private void methodB() {
System.out.println("B running.");
}Panama
Panama项目目标是增强JVM和本地代码的交互性,正在探索的改进:
- 外部内存访问支持
- 外部函数访问支持
- jextract工具
- 向量计算API
参考文献
https://openjdk.java.net/projects/panama/
外部内存访问支持
提供有效的内存段API直接操作堆外内存,可以对内存段进行安全访问控制,内存段切片、内存访问句柄。
从官方提供的资料看,内存段API可以加强堆内存和非堆内存的互通性,MemorySegment和Buffer、原生数组可以互相转化。
预览
// 申请堆外内存段,AutoCloseable确保内存在使用结束后释放
try (MemorySegment segment = MemorySegment.allocateNative(4096)) {
// 内存段切片,父内存段关闭时一并释放,切片关闭时也一并释放
MemorySegment slice = segment.asSlice(4, 4);
// 从堆外内存读取整数数组到堆中
VarHandle intHandle = MemoryHandles.varHandle(int.class, ByteOrder.nativeOrder());
int[] values = new int[1024];
for (int i = 0 ; i < values.length ; i++) {
values[i] = (int) intHandle.get(segment, (long)i * 4);
}
}外部函数访问支持
云原生时代,赋予Java更强大的调用本地库能力。有点类似JNI,但是更强大。
结合内存段API可以使用C函数直接对堆内的数组进行排序,不需要将数组拷贝到堆外内存中。
C标准库定义
void qsort(void *base, size_t nmemb, size_t size,
int (*compar)(const void *, const void *));Java封装
MethodHandle qsort = CLinker.getInstance().downcallHandle(
LibraryLookup.ofDefault().lookup("qsort").get(),
MethodType.methodType(void.class, MemoryAddress.class, long.class, long.class, MemoryAddress.class),
FunctionDescriptor.ofVoid(C_POINTER, C_LONG, C_LONG, C_POINTER)
);jextract工具
上面的外部函数访问API,实际的代码使用起来仍然是比较繁琐的。jextract是一个简单方便的工具,可以为C语言.h头文件生成对应的Java接口,直接在Java语言中调用。云原生时代,压榨机器性能到极致。
命令行将C代码打成jar包
jextract -t org.hello -lhelloworld helloworld.hJava中调用
import static org.hello.helloworld_h.*;
public class HelloWorld {
public static void main(String[] args) {
helloworld();
}
}向量计算API
提供平台无关、清晰简洁、CPU利用率高的向量计算API
原来的代码实现方式
void scalarComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}使用向量API的实现方式
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_256;
void vectorComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i += SPECIES.length()) {
var m = SPECIES.indexInRange(i, a.length);
// FloatVector va, vb, vc;
var va = FloatVector.fromArray(SPECIES, a, i, m);
var vb = FloatVector.fromArray(SPECIES, b, i, m);
var vc = va.mul(va).
add(vb.mul(vb)).
neg();
vc.intoArray(c, i, m);
}
}
0条评论