

Elasticsearch简介
- 基于Lucene的实时分布式搜索分析引擎
- 分布式json文档存储
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
集群和节点
- 一个运行中的 Elasticsearch 实例称为一个节点
- 集群是由一个或者多个拥有相同 cluster.name 配置的节点组成
- 集群选举出一个主节点,它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等
- 我们可以将请求发送到集群中的任何节点,每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点
索引和分片
- 集群可以创建和管理多个索引(索引的概念类似于关系数据库中的数据库)
- 一个索引的数据存储在若干个主分片中(索引是一个逻辑概念,一个分片是一个底层的工作单元,一个分片是一个 Lucene 的实例)
- 每个主分片可以有若干个副本分片(一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。)
- 默认情况下,一个索引有5个主分片,每个主分片有一个副本分片。主分片的数量不可改变,副本分片的数量可以动态调整
PUT /articles {
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}创建索引时应该指定多少个主分片呢?
5个主分片的默认值适用大多数情况,如果存储数据量很大,可以按照每个分片10GB大小的容量来预估需要多少个主分片
集群健康状态
- 绿:所有的主分片和副本分片都正常运行。
- 黄:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
- 红:有主分片没能正常运行。
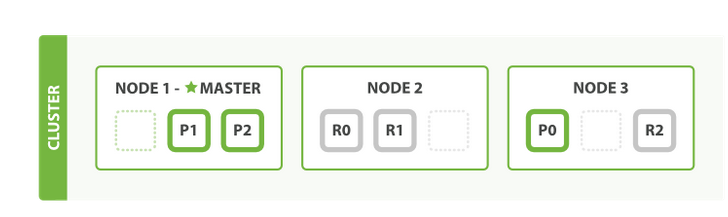
Elasticsearch分布式特性
- 文档分配到不同的分片中,文档可以储存在一个或多个节点中
- 按集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡
- 复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
- 将集群中任一节点的请求路由到存有相关数据的节点
- 集群扩容时无缝整合新节点,重新分配分片以便从离群节点恢复
路由routing
- 路由决定了文档存储写入到哪个主分片
- 默认情况下,根据文档的id的hash值取模进行路由:shard = hash(routing) % number_of_primary_shards
- 可以手动指定routing字段,查询和写入都会根据指定的routing字段路由到匹配的分片进行操作
- 一个routing值可以散列到多个分片,用于均衡热点routing
一致性consistency
- quorum:默认值,为了避免在发生网络分区故障,大多数的分片副本状态没问题才允许执行写操作 >= int( (primary + number_of_replicas) / 2 ) + 1
- all:必须要主分片和所有副本分片的状态没问题才允许执行写操作
- one:只要主分片状态 ok 就允许执行写操作
执行分步式检索
- 客户端以轮询的方式将请求均衡地发送到集群中的每一个节点
- 接收到请求的节点作为协调节点,根据routing将请求转发到存储数据的分片;协调节点也是以轮询的方式选择主分片/副本分片
- 协调节点将各分片的查询结果汇总排序后返回
深度分页
如果进行分页查询并且翻到较深的页,from + size的值较大,每个执行检索的分片需要返回from + size大小的数据给协调节点。协调节点需要(from + size) * shards_number大小的空间临时存储所有分片的结果,在排序后保留size大小的数据,丢弃掉所有其他数据。
如果使用足够大的 from 值,排序过程可能会变得非常沉重,使用大量的CPU、内存和带宽,集群负载压力变大。
集群的默认配置 from + size的值最大为10000,可以动态调整此值。
强烈建议不要使用深分页,可以通过使用scroll查询禁用排序的方式从集群取回大量文档;或者每次查询时指定上一页查询结果字段作为条件以避免深度分页。
倒排索引
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
索引分段
倒排索引被写入磁盘后是不可改变的: 它永远不会修改。这样做的好处是:不需要锁、容易缓存、可压缩、磁盘顺序写性能高。
怎样在保留不变性的前提下实现倒排索引的更新?答案是: 用更多的索引。这就是分段的思想,每个段代表一个倒排索引,搜索时轮流查询所有段。
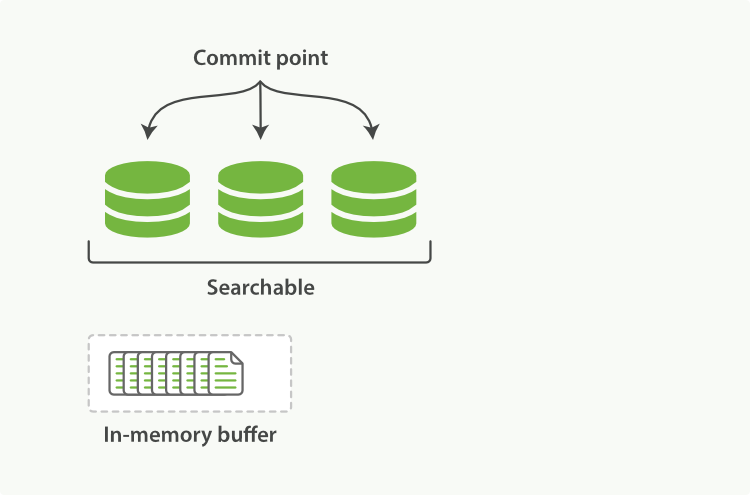
段生成过程:
- 新文档被收集到内存索引缓存
- 每过一段时间(默认每秒一次,通过fresh API可设置),缓存被提交,生成一个新的段
- 新的段写入文件系统缓存
- 新的段被标记为可见,即可搜索
- 内存缓存被清空,等待接收新的文档
段合并
每秒会创建一个新的段 会导致短时间内的段数量暴增,段越多,搜索也就越慢
Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。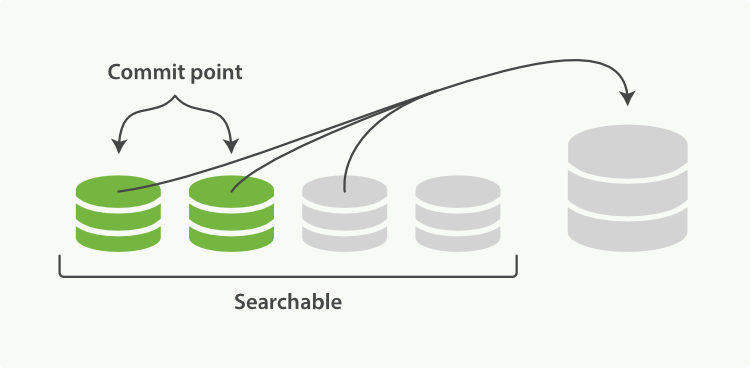
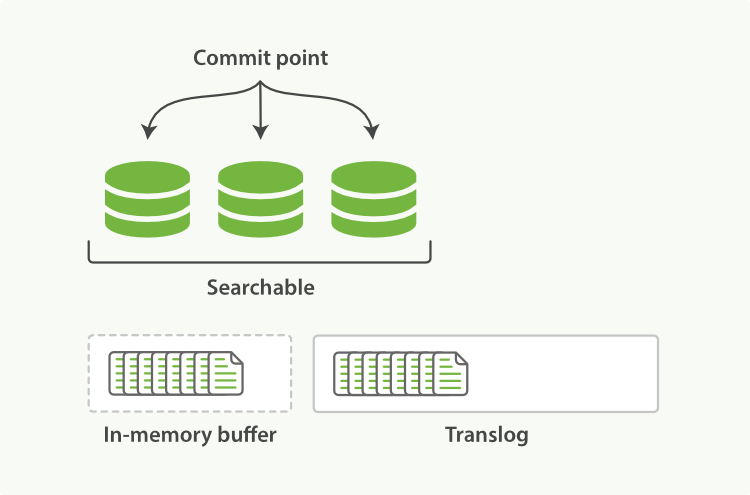
事务日志translog
为了避免断点丢失尚在内存或者文件系统缓存的段数据,每一次对 Elasticsearch 进行操作时均进行了日志记录
每30分钟执行或者在translog太大的时候执行flush
参考文档
Elasticsearch: 权威指南
中文,方便阅读,基于 Elasticsearch 2.x 版本,有些内容可能已经过时
Elasticsearch Reference
英文版文档,ES最新的稳定版本7.5
0条评论