

HBase是什么
列式存储数据库
一个分布式的、持久的、强一致性的存储系统,具有近似最优的写性能(能使I/O利用率达到饱和)和出色的读性能,它充分利用了磁盘空间,支持特定列族切换可选压缩算法
在分布式文件系统下提供实时随机存取数据能力
数十亿行 x 数百万列 x 数千个版本 = TB级或PB级的存储
Java语言编写
继承自BigTable模型,只考虑单一的索引,提供服务器端钩子,可以实施灵活的辅助索引解决方案
逻辑结构
表 -> 行 -> 列族 -> 列 -> 时间戳 -> 单元格
table -> row -> columnFamily -> columnQualifier -> timestamp -> cell
SortedMap<RowKey, List<SortedMap<Column, List<Value, Timestamp>>>>
行键
唯一
按照二进制升序排序
列族
需要预定义
数量不能太多
不同列族存储的数据位于不同的HFile中
列
数量没有限制
有序
时间戳
默认使用服务器时间,也可以从客户端自定义,可以设置最多保留最近的N个版本
概要视图
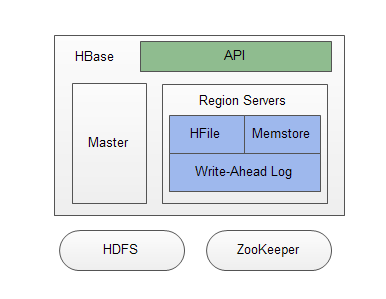
客户端API
- GET
- SCAN
- PUT
- DELETE
- ADMIN
特性
- 支持单行事务(单行读-修改-写的原子性)
- 计数器
- 支持服务端过滤
- 协处理器(类似于关系数据库的触发器 + 自定义函数)
实现机制
- LSM树(write-ahead log, WAL)
- master管理节点和region服务节点
- HDFS存储实际数据
- 布隆过滤器查找包含指定行键的块
HDFS协作
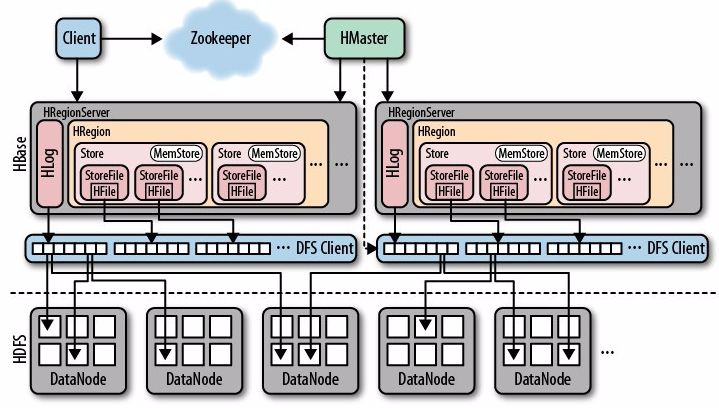
HMaster
- 管理表的元数据
- 监控RegionServer
- Region分发
HRegionServer
实际工作节点,管理若干个Region
Region
以行键排序的连续存储区间
Region拆分
达到hbase.hregion.max.filesize定义的大小由进行拆分,重新负载均衡
HFile文件结构
若干个数据块,及文件信息
数据块大小默认为64KB
HFile合并
minor合并
将多个HFile多路归并,简单按序累加
major合并
将一个region中一个列族的若干个HFile重写为一个新的HFile
压缩合并,移除应删除的cell
0条评论